728x90
10 텍스트 마이닝
10-1 힙합 가사 텍스트 마이닝
- 텍스트 마이닝(Text mining) : 문자로 된 데이터에서 가치 있는 정보를 얻어 내는 분석 기법
- 형태소 분석(Morphology Analysis)
- 텍스트 마이닝을 할 때 가장 먼저 하는 작업
- 문장을 구성하는 어절들이 어떤 품사로 되어 있는지 파악
- 어절들의 품사를 파악한 후 명사, 동사, 형용사 등 의미를 지닌 품사의 단어들을 추출해 각 단어가 얼마나 많이 등장했는지 확인
# 패키지 로드 library(KoNLP) library(dplyr) useNIADic() # 데이터 불러오기 txt <- readLines(file("./data/hiphop.txt", encoding = "UTF-8")) head(txt) ## [1] "\"보고 싶다" "이렇게 말하니까 더 보고 싶다" ## [3] "너희 사진을 보고 있어도" "보고 싶다" ## [5] "너무 야속한 시간" "나는 우리가 밉다" library(stringr) # 특수문자 제거 txt <- str_replace_all(txt, "\\W", " ") # 가사에서 명사 추출 nouns <- extractNoun(txt) # 추출한 명사 list를 문자열 벡터로 변환, 단어별 빈도표 생성 wordcount <- table(unlist(nouns)) # 데이터 프레임으로 변환 df_word <- as.data.frame(wordcount, stringsAsFactors = F) # 변수명 수정 df_word <- rename(df_word, word = Var1, freq = Freq) # 두 글자 이상 단어 추출 df_word <- filter(df_word, nchar(word) >= 2) top_20 <- df_word %>% arrange(desc(freq)) %>% head(20) top_20 ## word freq ## 1 you 89 ## 2 my 86 ## 3 YAH 80 ## 4 on 76 ## 5 하나 75 ## 6 오늘 51 ## ... # 패키지 로드 library(wordcloud) library(RColorBrewer) # Dark2 색상 목록에서 8개 색상 추출 pal <- brewer.pal(8, "Dark2") set.seed(1234) wordcloud(words = df_word$word, # 단어 freq = df_word$freq, # 빈도 min.freq = 2, # 최소 단어 빈도 max.words = 200, # 표현 단어 수 random.order = F, # 고빈도 단어 중앙 배치 rot.per = .1, # 회전 단어 비율 scale = c(4, 0.3), # 단어 크기 범위 colors = pal) # 색상 목록 ## 많이 사용된 단어일수록 글자가 크고 가운데에 배치 ## 덜 사용된 단어일수록 글자가 작고 바깥쪽에 배치되는 형태로 구성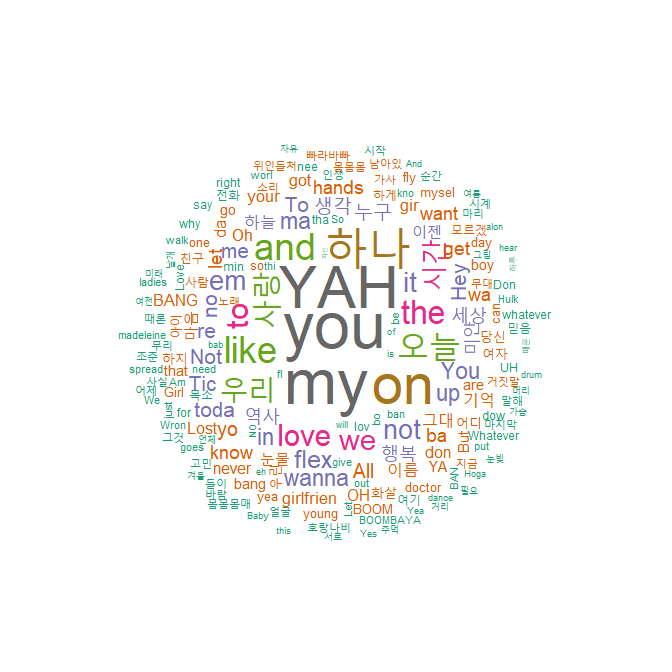
- 형태소 분석(Morphology Analysis)
10-2 국정원 트윗 텍스트 마이닝
- 텍스트 마이닝은 소셜 네트워크에 올라온 글을 통해 사람들이 어떤 생각을 하고 있는지 알아보기 위한 목적으로 자주 활용
- 해당 데이터는 국정원이 대선에 개입한 사실이 밝혀져 논란이 됐던 2013년 6월, 독립 언론 뉴스타파가 인터넷을 통해 공개한 것으로
국정원 계정으로 작성된 3,744개 트윗으로 구성# 데이터 로드 twitter <- read.csv("./data/twitter.csv", header = T, stringsAsFactors = F, fileEncoding = "UTF-8") # 변수명 수정 twitter <- rename(twitter, no = 번호, id = 계정이름, date = 작성일, tw = 내용) # 특수문자 제거 twitter$tw <- str_replace_all(twitter$tw, "\\W", " ") head(twitter$tw) ## [1] "민주당의 ISD관련 주장이 전부 거짓으로 속속 드러나고있다 미국이 ISD를 장악하고 있다고 주장하지만 중재인 123명 가운데 ## 미국인은 10명뿐이라고 한다 " ## [2] "말로만 미제타도 사실은 미제환장 김정일 운구차가 링컨 컨티넬탈이던데 북한의 독재자나 우리나라 종북들이나 겉으로는 ## 노동자 서민을 대변한다면서 고급 외제차 아이팟에 자식들 미국 유학에 환장하는 위선자들인거죠" ## ... # 트윗에서 명사추출 nouns <- extractNoun(twitter$tw) # 추출한 명사 list를 문자열 벡터로 변환, 단어별 빈도표 생성 wordcount <- table(unlist(nouns)) # 데이터 프레임으로 변환 df_word <- as.data.frame(wordcount, stringsAsFactors = F) # 변수명 수정 df_word <- rename(df_word, word = Var1, freq = Freq) # 두 글자 이상 단어만 추출 df_word <- filter(df_word, nchar(word) >= 2) # 상위 20개 추출 top20 <- df_word %>% arrange(desc(freq)) %>% head(20) top20 ## word freq ## 1 종북 2431 ## 2 북한 2216 ## 3 세력 1162 ## 4 좌파 829 ## 5 대한민국 804 ## 6 우리 780 ## 7 들이 566 ## 8 국민 550 ## 9 친북 430 ## ... ## 북한, 좌파, 친북, 김정일, 천안함, 연평도 등 북한과 관련된 단어들이 자주 사용된 것을 보면, ## 국정원이 안보 위협을 강조하는 트윗을 주로 작성했다는 것을 알 수 있음 library(ggplot2) order <- arrange(top20, freq)$word # 빈도 순서 변수 생성 ggplot(data = top20, aes(x = word, y = freq)) + ylim(0, 2500) + geom_col() + coord_flip() + scale_x_discrete(limit = order) + # 빈도순 막대 정렬 geom_text(aes(label = freq), hjust = -0.3) # 빈도 표시 ## 가장 많이 사용된 단어인 '종북', '북한'이 '대한민국'의 세 배 가까이 될 정도로 많은 것을 보면 ## 국정원이 북한 관련 이슈에 초점을 맞추고 트윗을 작성했다는 것을 알 수 있음 pal <- brewer.pal(8, "Dark2") # 색상 목록 생성 set.seed(1234) # 난수 고정 wordcloud(words = df_word$word, # 단어 freq = df_word$freq, # 빈도 min.freq = 10, # 최소 단어 빈도 max.words = 200, # 표현 단어 수 random.order = F, # 고빈도 단어 중앙 배치 rot.per = .1, # 회전 단어 비율 scale = c(6, 0.2), # 단어 크기 범위 colors = pal) # 색상 목록
출처 : Do it! 쉽게 배우는 R 데이터 분석
Do it! 쉽게 배우는 R 데이터 분석
통계, 프로그래밍을 1도 몰라도 데이터를 혼자서 다룰 수 있다!데이터 분석 프로젝트 전 과정 수록!데이터 분석을 처음 시작한 초보자도 어깨춤을 추며 데이터를 혼자 다룰 수 있게 한다는 강의
book.naver.com
728x90
'Do it! > R' 카테고리의 다른 글
| Do it! 쉽게 배우는 R 데이터 분석 - 지도 시각화 (0) | 2021.03.05 |
|---|---|
| Do it! 쉽게 배우는 R 데이터 분석 - 그래프 만들기 (0) | 2021.02.27 |
| Do it! 쉽게 배우는 R 데이터 분석 - 데이터 정제 (0) | 2021.02.25 |